
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 17144
- 백준
- 6603
- 인스타그램
- Java
- 17472
- 다리 만들기2
- 17136
- 14888
- 댓글
- 장고
- 알고리즘
- 부분수열의 합
- 16637
- 따라하기
- 구슬탈출2
- 색종이 붙이기
- 미세먼지 안녕!
- 괄호추가하기
- 좋아요
- 연산자 끼워넣기
- 인스타
- django
- 로또
- 17143
- 14502
- 재귀
- 1182
- Ajax
- 9095
- Today
- Total
Be a developer
2. 간단한 사용 및 개념 정리 본문
zookeeper
카프카와 연결하기 전 아래 명령어를 쳐보면 zookeeper 노드만 존재
# bin 디렉토리로 이동
$ ./zkCli.sh
# zookeeper cli가 실행된 후
> ls /카프카와 연결한 후 다시 ls / 명령어를 실행하면 여러 노드가 생성된 것이 보인다.

디렉토리들을 살펴본다.(아직은 아래 디렉토리에만 데이터가 존재한다.)

kafka-manager
cluster를 추가해준다.
cluster 추가 후 다시 zookeeper에 접속해서 노드를 찾아본다.
__consumer_offsets라는 토픽이 추가되어 있다.
consumer group이 consume하는 topic partition에 대하여 어디까지 consume했는지를 해당 토픽에 저장한다고함.

카프카 매니저를 통해 cluster 및 토픽을 간단하게 추가했다.

zookeeper로 보면 topic이 추가된 것을 볼 수 있다.


topic & partition
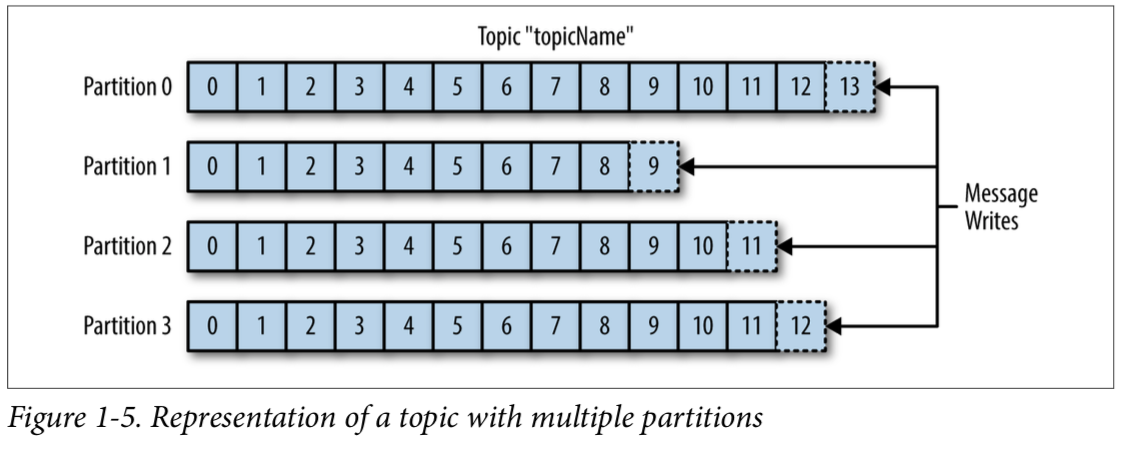
- message
- kafka에서 데이터의 기본단위이다.
- topic
- 여러 개의 partition으로 구성될 수 있다.
- partition
- message가 추가되는 queue
- 각 partition은 서로 다른 서버에 분산될 수 있다.
producer & consumer
PRODUCER
- 새로운 message를 생성.
- message는 특정 topic으로 생성.
- 기본적으로 producer는 메시지가 어떤 partition에 수록되는지 관여하지 않는다.
- 그러나 때로 특정 partition에 message를 직접 쓰는 경우가 있다.
- 이 때는 message key와 partitioner를 사용한다.
- partitioner는 key의 hash값을 생성하고 이를 특정 partition에 대응시킴으로써 특정 key가 항상 같은 partition에 수록되게 해준다.
CONSUMER
- message를 읽는다.
- 하나 이상의 topic을 구독하여 message가 생성된 순서로 읽는다.
- message의 offset을 유지하여 읽는 message의 위치를 알 수 있다.
- offset은 message가 생성될 때 kafka가 추가해준다.
- offset은 증가되는 값으로 하나의 partition에서 각 message는 고유한 값을 갖는다.
- zookeeper나 kafka에서는 각 partition에서 마지막에 읽은 message의 offset을 저장하고 있으므로, consumer가 message 읽기를 중단했다가 다시 시작해도 언제든 그 다음 message부터 읽을 수 있다.
CONSUMER GROUP
- 하나 이상의 consumer로 구성
- 하나의 topic을 소비하기 위해 같은 group의 여러 consumer가 함께 동작한다.
- 하나의 topic의 각 partition은 하나의 consumer만 소비할 수 있다.
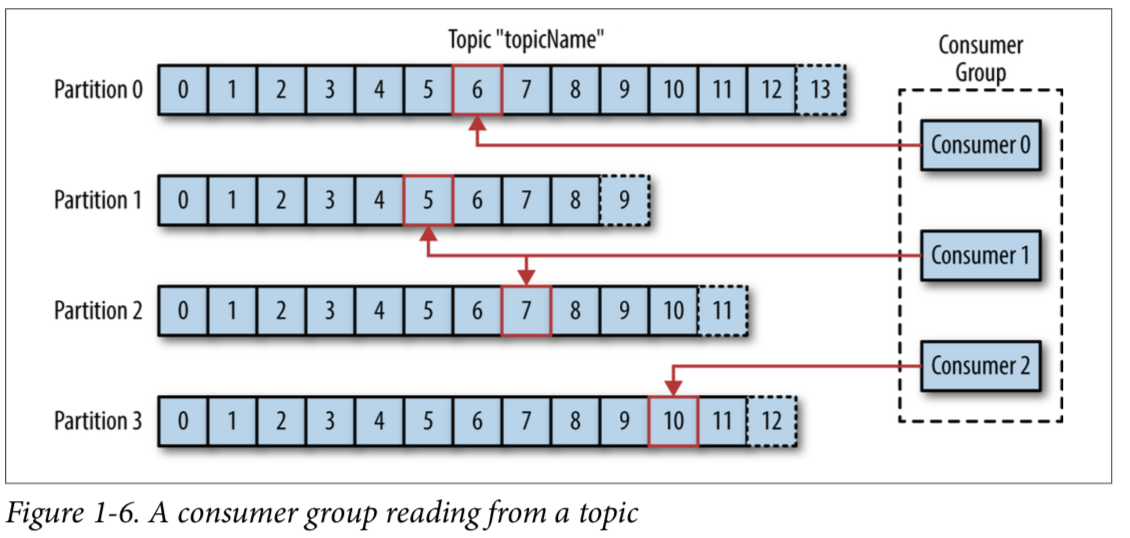
위 그림에서 두 consumer는 각각 하나의 partition을 소비하고, 나머지 consumer는 두 개의 partition을 소비한다.
하나의 consumer가 자기 소유의 partition에 있는 message를 읽는 데 실패하더라도 같은 group의 다른 consumer가 partition 소유권을 재조정받은 후 실패한 consumer의 partition message를 대신 읽을 수 있다.
broker & cluster
하나의 kafka 서버를 broker라 한다.(나는 3개의 서버 즉, 3개의 broker를 설치했다.)
broker는 producer로 부터 message를 수신하고 offset을 지정한 후, 해당 message를 디스크에 저장한다.
또한 consumer의 partition 읽기 요청에 응답하고 디스크에 수록된 message를 전송한다.
broker는 cluster의 일부로 동작한다.
즉, 여러 개의 broker가 하나의 cluster를 구성한다.
그 중 하나는 자동으로 선정되는 cluster controller의 기능을 수행한다.
controller는 같은 cluster의 각 broker에게 담당 partition을 할당하고 broker들이 정상적으로 동작하는지 모니터링하는 관리 기능을 맡는다.
각 partition은 cluster의 한 broker가 소유하며 그 broker를 partition leader라고 한다.
또한, 같은 partition이 여러 broker에 저장될 수도 있는데, 이 때는 해당 partition이 replication된다.
각 partition을 사용하는 모든 consumer와 producer는 partition leader에 연결해야 한다.
또 kafka의 핵심기능은 retention이다.
기간 혹은 용량을 기준으로 message를 보관하는 얼마나 보관할지 정할 수 있다.
topic마다 retention을 다르게 가져갈 수도 있다.
replication
Kafka 운영자가 말하는 Topic Replication | Popit
kafka는 다른 애플리케이션 등에서 사용하는 replication과는 조금 다른 개념의 replication 방식을 사용하고 있습니다. kafka replication를 이해하기 위해 kafka에서 사용되는 replication 관련 몇 가지 용어들
www.popit.kr
정리하면
1. topic을 생성할 떄 Replication Factor를 설정할 수 있다.
2. Replication Factor가 3이라면 1대는 leader가 되고, 2대는 follower가 된다.
3. message read/write는 leader로 부터 이루어진다.
4. follower는 leader로 부터 data를 pull 해서 sync를 유지한다.
5. 이러한 leader와 follower를 ISR(In Sync Replica)이라 한다. Replication Group이라 생각하면 쉽다.
6. leader topic을 가진 broker가 죽으면 follower 중에서 leader를 선출한다.
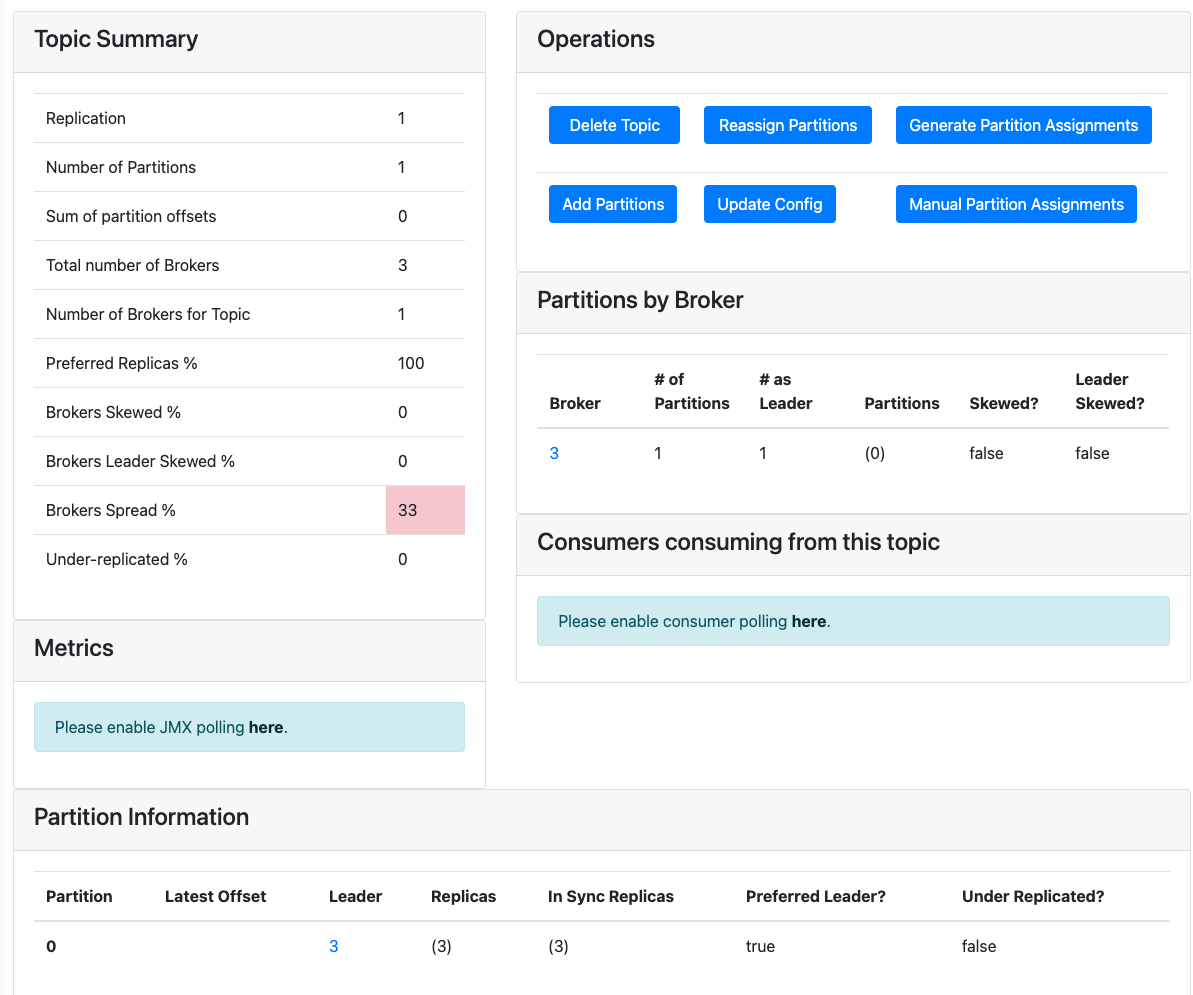
그런데 아래와 같이 kafka manager에서 보면 topic 단위가 아니라 partition 단위로 leader가 있다.
참조: needjarvis.tistory.com/604
[카프카] 리더, 팔로워와 리플리케이션(replication)
카프카에서는 파티션 단위로 분산처리를 수행한다. 이 분산 처리를 할 때 핵심적인 기능이 바로 복제(Replication)이라 볼 수 있다. 분산 처리를 할 때에는 모든 브로커에 데이터를 동일하게 보내는
needjarvis.tistory.com
사실은 topic이 아닌 partition 단위로 replication이 이루어진다.
여담으로 partition개수보다 Replication Factor를 크게 설정하면 오류가 발생한다.
'Kafka' 카테고리의 다른 글
| 4. Consumer (0) | 2021.04.12 |
|---|---|
| 3. Producer (0) | 2021.04.07 |
| 1. 설치 (0) | 2021.03.19 |


