
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 색종이 붙이기
- 미세먼지 안녕!
- 따라하기
- 장고
- 14502
- 17144
- 1182
- 17136
- 연산자 끼워넣기
- 인스타
- 6603
- 재귀
- 괄호추가하기
- 좋아요
- 로또
- Java
- 16637
- 17472
- 다리 만들기2
- 백준
- 구슬탈출2
- 14888
- Ajax
- 인스타그램
- 댓글
- django
- 9095
- 부분수열의 합
- 17143
- 알고리즘
- Today
- Total
Be a developer
3. Producer 본문
kafka에 message를 producing할 때 요구 조건은 다양하다.
- 신용카드 트랜잭션
온라인 상점 등에서 대금 결제가 되는 즉시 kafka에 transaction 데이터를 전송한다. 이 때 하나의 message도 유실되지 않아야 하고, message가 복제되어도 안된다.
또한 처리 대기 시간은 짧아야 하고, 처리량은 매우 많아야 한다.
- 웹 사이트의 클릭 정보
일부 message의 유실이나 복제가 허용될 수 있다.
사용자 경험에 영향을 주지 않는 범위에서 대기 시간이 길어도 된다. 즉, 사용자가 웹 페이지의 링크를 클릭할 때 다음 페이지가 로드만 될 수 있다면, message가 kafka에 전달되는 데는 수 초가 걸려도 괜찮다.
처리량은 웹 사이트의 접속량에 따라 다를 수 있다.
Producer API

1. ProducerRecord
- 전송하길 원하는 topic과 value를 포함
- 선택적으로 key와 partition을 지정할 수 있음.
2. ProducerRecord를 kafka로 전송하기 전에 가장 먼저 하는 일은 message(key-value)가 네트워크로 전송될 수 있도록 byte 배열로 serialize하는 것이다.
3. 그 다음 해당 데이터는 Partitioner에 전달된다. 만약 ProducerRecord에 특정 partition을 지정했다면 partitioner는 특별한 처리를 하지 않고 지정된 partition을 반환한다.
하지만 partition을 지정하지 않았다면 ProducerRecord의 key를 기준으로 Partitioner가 하나의 partition을 선택해준다.
4. 같은 topic과 partition으로 전송될 record들을 모은 record batch에 추가하여, 별개의 thread가 그 batch를 kafka broker에 전송한다.
5. broker는 수신된 record의 message를 처리한 후 응답을 전송한다. message를 성공적으로 쓰면 RecordMetadata 객체를 반환한다.
RecordMetadata는 topic, partition, offset을 갖는다.
Producer 객체 설정
1. bootstrap.servers
- kafka cluster에 최초로 연결하기 위해 producer가 사용하는 broker들의 host: port 목록을 해당 속성에 설정.
- 모든 broker 목록을 포함할 필요가 없음. 하나의 broker와 연결되면 더 많은 정보를 얻을 수 있기 때문
- 최소한 2개의 broker를 포함하는 것이 좋다. 하나의 broker가 중단되는 경우를 대비하기 위해.
- 혹은 VIP로 묶으면 될듯.
2. key.serializer
- producer가 생성하는 record의 message key를 serialize하기 위해 사용되는 클래스 이름을 설정.
3. value.serializer
- producer가 생성하는 record의 message value를 serialize하기 위해 사용되는 클래스 이름을 설정.
Producing
1. 하나의 topic에 producing 해본다.
우선 아래와 같이 producer를 만든다.

그리고 간단하게 메세지를 producing한다.

kafka manager에서 제대로 들어갔는지 offset 확인을 해본다.

안떠서 명령어로 확인 해본다.

application을 몇 번을 동작시켜도 증가하지 않는다..
아래와 같이 결과를 확인하는 코드를 추가한다.

kafka manager에는 여전히 offset이 나타나지 않지만 터미널에서 명령어로 보면 아래와 같이 증가되었다.

명령어로 consume 해보면 잘 들어간 것을 확인할 수 있다.

Kafka Producer의 전송방식에는 3가지 방법이 있다.
- Fire-and-forget
- Syncronous
get()으로 전송 결과를 받는다.
- Asyncronous
전송하고 결과를 기다리지 않는다.
처음 코드에서는 비동기적으로 message를 전송했기 때문에 위의 producer 그림에서 본 것 처럼 buffer에 message가 들어간 상태이고 전송은 되지 않은 상태로 application이 종료되었다.
하지만 두 번째 코드에서는 동기적으로 전송하고 전송에 성공했다는 결과를 받았다. 즉, 전송까지 모두 마치고 결과까지 성공적으로 받은 후 application이 종료된 것이다.
그래서 해당 topic의 partion에 대한 offset을 확인했을 때 증가한 것이다.
따라서 지금 작성한 application처럼 하나의 message만 보내고 종료하는 경우 flush 메소드를 호출하여 buffer를 비워주면 하나의 message라도 전송되는 것을 확인할 수 있다.
이렇게 비동기로 처리하는 이유는
- 모든 message마다 결과를 받을 경우(동기적으로 처리할 경우)
1. send 호출시 I/O Block이 발생하여 병렬성이 떨어진다.
- 비동기적이라면 thread를 생성하여 message전송을 담당. producer는 다시 다른 send를 수행한다. (message전송이 병렬로 이루어짐)
- 동기적으로 진행한다면 결과를 받을 때까지 producer의 send가 수행되지 않음.(message 전송이 병렬로 이루어지지 않음)
2. Bulk로 보내는 것 보다 Network Overhaed가 발생한다.
코드상으로 어떻게 동작하는지 코드를 뜯어본다.
ProducerRecord

생성자를 보면 topic이 null이면 exception이 발생한다.
headers는 아래 생성자처럼 null이 오면 empty arrayList를 만든다.

KafkaProducer
send 메소드를 보면 아래와 같은 코드들이 나온다.. 길다..


먼저 doSend1의 waitOnMetadata를 보자.

간략하게 보면
1. metadata를 fetch
2. metadata에 producing 대상 topic을 추가하고, sender를 깨운다.
3. metadata가 update될 때까지 기다린다.
4. metadata가 update되면 해당 정보를 return 한다.
사진에서 짤렸지만 메소드에 대한 설명이 있다.

여담으로 metada.fetch() 메소드를 보면 metadata는 cache해놓고 쓴다는 것을 알 수 있다.
이후에는 key, value를 serialize하고, producing할 partition을 선택한다.

send 메소드에 partition을 지정했다면 해당 partition으로 producing할 것이고, 없었다면 partitioner에 의해 결정된다.
그리고 accmulator에 append한다.

그리고 append 내부에서 아래와 같이 deque를 가져온다.
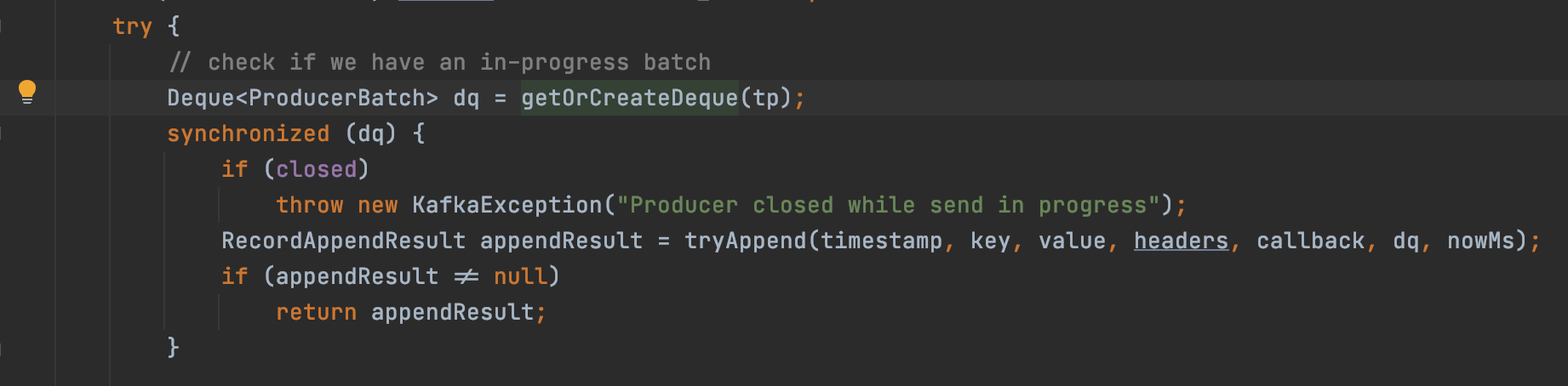
이는 RecordAccumulator의 batches라는 map에서 topic & partition에 해당하는 deque를 가져오는 것이다.


이를 통해 topic & partition마다 deque가 있는 것을 알 수 있다.
참조: leeyh0216.github.io/2020-05-03/kafka_producer
간단한 Kafka Producer를 만들고 동작원리를 알아보자
Kafka Producer
leeyh0216.github.io
Sender는 KafkaProducer가 생성될 때 생성된다.
Daemon thread로 동작하며 RecordAccumulator의 beffer에 있는 message를 kafka cluster로 producing한다.

참조: jaceklaskowski.gitbooks.io/apache-kafka/content/kafka-producer-internals-Sender.html
Sender · The Internals of Apache Kafka
jaceklaskowski.gitbooks.io
참조: d2.naver.com/helloworld/6560422
위의 코드에서 test topic이 아니라 test1 topic으로 producing을 하면 topic이 생성되고, message가 producing된다.
2. 하나의 topic에 3개의 producer가 producing한다.

partition이 하나밖에 없으니 하나의 파티션에 message가 다 들어간다.
3. topic의 partition을 3개로 만들고, 3개의 producer가 producing한다.

key가 1로 다 동일하고, partition을 설정하지 않았으므로 같은 partition으로 message가 들어간다.
key를 random으로 만들도록 하고 동작시켜 보았다.

다시 한 번

해당 topic의 partition은 3개이고, Replication Factor도 3으로 설정했고, 따라서 broker마다 3개의 partition을 가지고 있다.
그리고 partition마다 leader는 분산되어 배치되었다.


4. 하나의 topic에 producing하다가, 해당 topic에 있는 모든 partition의 특정 offset부터 다른 topic으로 producing 해본다.
만약 어떤 consumer group이 topic을 소비하다가 알 수 없는 문제가 발생해 소비를 하지 못하는 상황일 때, 이를 해결할 수 있으면 가장 좋지만, 해당 consumer group을 변경하여, 실패한 offset부터 다시 소비할 수 있도록 할 수 있다.
예를 들어 어떤 서버군이 test1이라는 group id를 사용하여 test라는 topic을 소비하고 있었다. 그런데 알 수 없는 에러가 발생해서 소비를 하지 못하고 있을 때, 간단한 방법은 해당 서버군이 test2라는 group id를 사용하도록 변경하고, 기존 offset부터 다시 test topic을 소비하도록 변경해주면 된다.
1) 기존 A토픽을 소비하던 a서버군을 내리고, B토픽을 새로 만든다.
2) b 서버군을 투입하여 A토픽을 consume하여 B토픽으로 producing한다.
3) a 서버군이 B 토픽을 소비하도록 변경한다.
'Kafka' 카테고리의 다른 글
| 4. Consumer (0) | 2021.04.12 |
|---|---|
| 2. 간단한 사용 및 개념 정리 (0) | 2021.04.04 |
| 1. 설치 (0) | 2021.03.19 |


